
Neven Pičuljan
Verified Expert in Engineering
Co-founder of Poze and CEO of an AI R&Neven拥有MCS学位,并在TensorFlow中建立了一个面部识别系统.
Expertise
Years of Experience
7
Co-founder of Poze and CEO of an AI R&Neven拥有MCS学位,并在TensorFlow中建立了一个面部识别系统.
7
In classical programming, 软件指令是由程序员明确制定的,从数据中根本学不到任何东西. In contrast, 机器学习是计算机科学的一个领域,它使用统计方法使计算机能够学习并从数据中提取知识,而无需明确编程.
In this reinforcement learning tutorial, 我将展示如何使用PyTorch教强化学习神经网络如何玩《欧博体育app下载》. 但首先,我们需要介绍一些构建模块.
机器学习算法大致可以分为两部分:传统学习算法和 deep learning algorithms. 传统学习算法的可学习参数通常比深度学习算法少得多,学习能力也小得多.
而且,传统的学习算法无法做到这一点 feature extraction人工智能专家需要找出一个好的数据表示,然后将其发送给学习算法. 传统机器学习技术的例子包括支持向量机, random forest, decision tree, and $k$-means, 而深度学习的核心算法是 deep neural network.
深度神经网络的输入可以是原始图像, 人工智能专家不需要找到任何数据表示——神经网络在训练过程中找到最佳表示.
很多深度学习技术已经存在很长时间了, 但最近硬件的进步迅速推动了深度学习的研究和开发. 英伟达负责该领域的扩展,因为它的gpu使快速深度学习实验成为可能.
机器学习算法包括在训练过程中调整的可学习参数和在训练过程之前设置的不可学习参数. 在学习之前设置的参数被调用 hyperparameters.
Grid search 寻找最优超参数的常用方法是什么. 这是一种蛮力方法:它意味着在定义的范围内尝试所有可能的超参数组合,并选择最大化预定义度量的组合.
对学习算法进行分类的一种方法是在监督算法和无监督算法之间划清界限. (但这并不一定那么简单: Reinforcement learning 介于这两种类型之间.)
当我们讨论监督学习时,我们看$ (x_i, y_i) $对. $ x_i $是算法的输入,$ y_i $是输出. 我们的任务是找到一个函数,它将做从$ x_i $到$ y_i $的正确映射.
为了调整可学习参数,它们定义了一个将$ x_i $映射到$ y_i $的函数, 需要定义损失函数和优化器. An optimizer minimizes the loss function. 损失函数的一个例子是均方误差(MSE):
\[MSE = \sum_{i=1}^{n} (y_i - \widehat{y_i})^2\]这里,$ y_i $是一个基本真实标签,$ \widehat{y_i} $是一个预测标签. 一个在深度学习中非常流行的优化器是 stochastic gradient descent. 有很多尝试改进随机梯度下降法的变体, Adadelta, Adagrad, and so on.
无监督算法试图在没有明确提供标签的情况下找到数据中的结构. $k$-means是试图在数据中找到最优聚类的无监督算法的一个例子. Below is an image with 300 data points. k -means算法找到数据中的结构,并为每个数据点分配一个聚类标签. Each cluster has its own color.

强化学习使用奖励:稀疏的、延迟的标签. An agent takes action, which changes the environment, 它可以从中得到新的观察和奖励. 观察是一个主体从环境中感知到的刺激. 它可以是代理看到的,听到的,闻到的,等等.
当代理采取行动时,会给它奖励. 它告诉agent这个动作有多好. 通过感知观察和奖励,智能体学习如何在环境中做出最佳行为. I’ll get into this in more detail below.
这种技术有几种不同的方法. 首先,我们在这里使用的是主动强化学习. In contrast, there’s passive reinforcement learning, 奖励只是另一种形式的观察, 而决策是根据固定的政策做出的.
Finally, 逆强化学习试图重建一个给定行为历史及其在不同状态下的奖励函数.
任何固定的参数和超参数实例都称为模型. 机器学习实验通常包括两个部分:训练和测试.
在训练过程中,使用训练数据调整可学习参数. In the test process, learnable parameters are frozen, 任务是检查该模型对以前未见过的数据的预测是否准确. 泛化是学习机器在新事物上准确执行的能力, 在经历了学习数据集之后看不见的例子或任务.
如果模型相对于数据来说过于简单, 它将无法拟合训练数据,并且在训练数据集和测试数据集上都表现不佳. In that case, we say the model is underfitting.
如果机器学习模型在训练数据集上表现良好, but poorly on a test dataset, we say that it’s overfitting. 过度拟合是指模型相对于数据过于复杂的情况. It can perfectly fit training data, 但是它太适应训练数据集了,以至于在测试数据i上表现不佳.e., it simply doesn’t generalize.
下图显示了总体数据与预测函数之间的平衡情况下的欠拟合和过拟合.

数据在构建机器学习模型中至关重要. 通常,传统的学习算法不需要太多的数据. 但由于它们的容量有限,性能也受到限制. 下图显示了与传统机器学习算法相比,深度学习方法的可扩展性.

神经网络由多层组成. 下图显示了一个简单的四层神经网络. 第一层是输入层,最后一层是输出层. 输入和输出层之间的两层是隐藏层.

如果一个神经网络有一个以上的隐藏层,我们称之为深度神经网络. 将输入集$ X $赋给神经网络,得到输出集$ y $. 学习是使用反向传播算法完成的,该算法结合了损失函数和优化器.
反向传播包括两个部分:向前传递和向后传递. 在正向传递中,将输入数据放到神经网络的输入端,得到输出. 计算真实值与预测值之间的损失, and then in the backward pass, 神经网络的参数根据损失进行调整.
One neural network variation is the convolutional neural network. It’s primarily used for computer vision tasks.
卷积神经网络中最重要的一层是卷积层(因此得名). 它的参数由可学习的过滤器组成,也称为核. 卷积层对输入应用卷积操作, passing the result to the next layer. 卷积操作减少了可学习参数的数量, 作为一种启发式,使神经网络更容易训练.
下面是卷积层中的卷积核是如何工作的. 将核函数应用于图像,得到卷积特征.
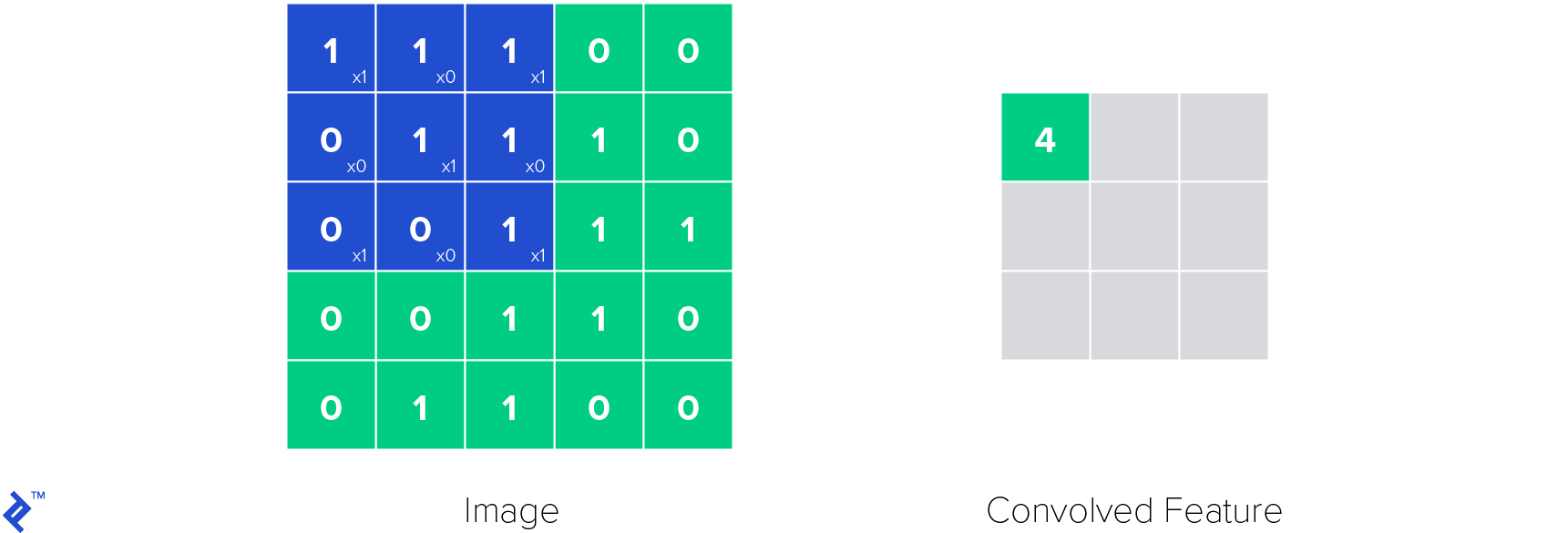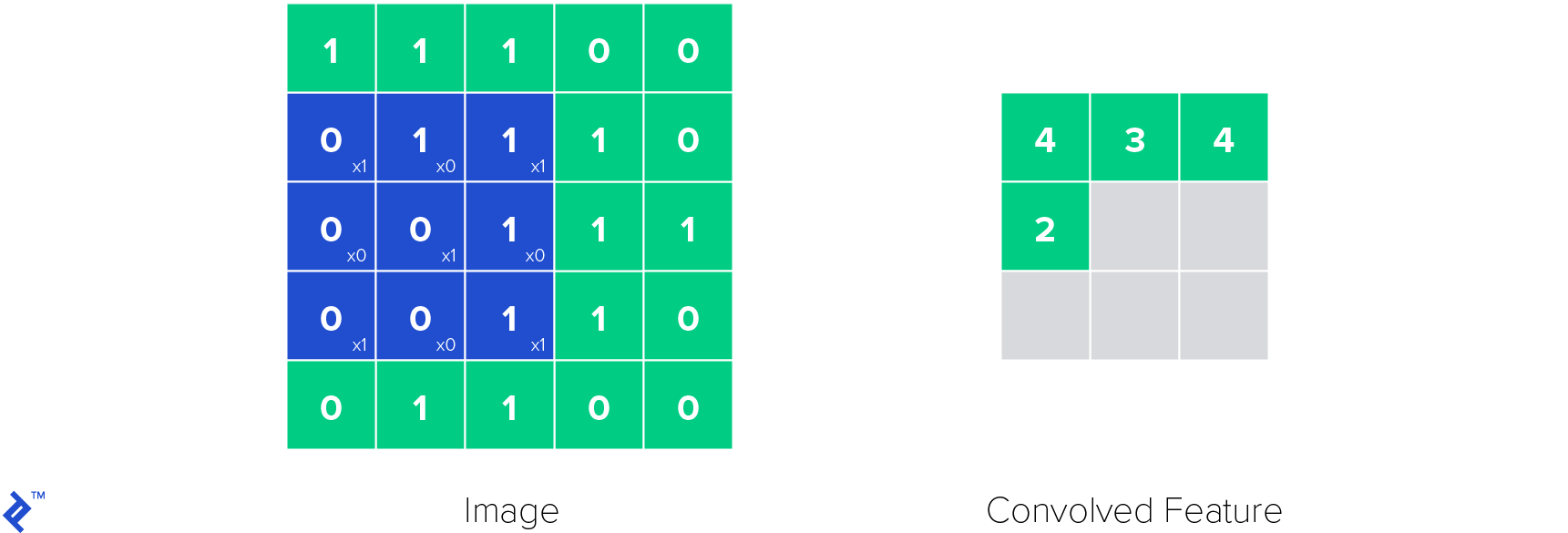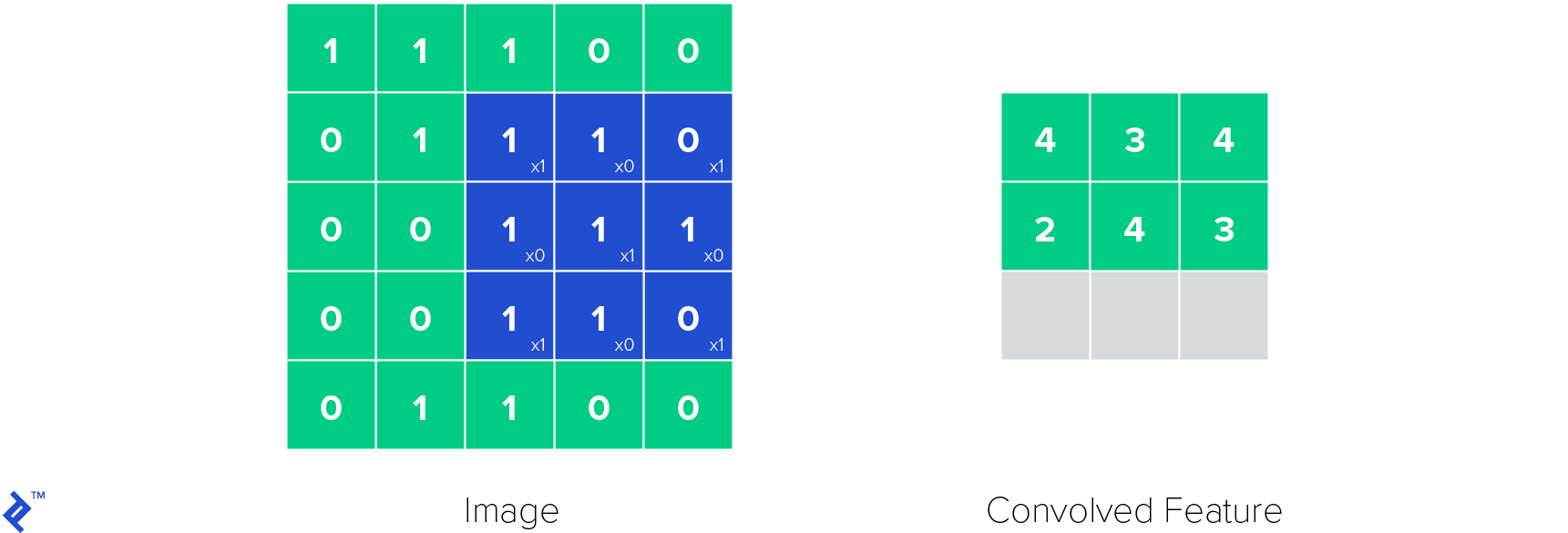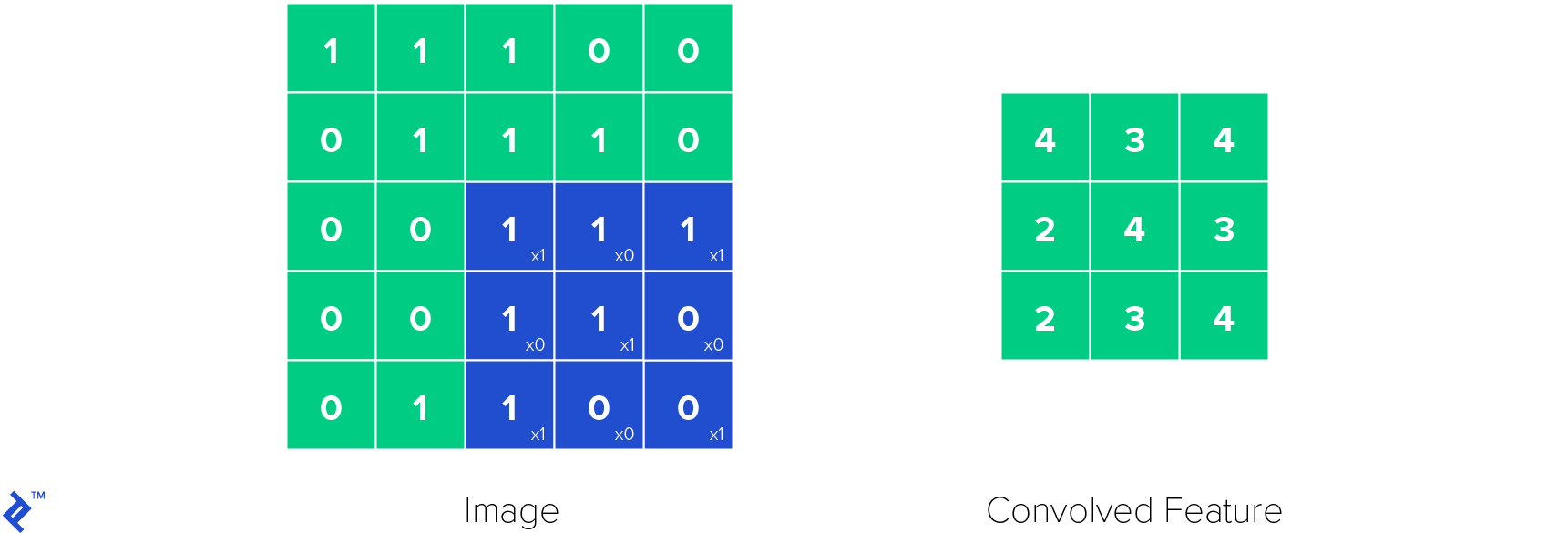
ReLU层用于在神经网络中引入非线性. 非线性很重要,因为有了它我们可以对各种函数建模, not only linear ones, 使神经网络成为通用函数逼近器. 这使得ReLU函数定义如下:
\[ReLU = \max(0, x)\]ReLU is one of the examples of so-called activation functions 用于在神经网络中引入非线性. 其他激活函数的例子包括sigmoid和超切线函数. ReLU是最受欢迎的激活函数,因为与其他激活函数相比,它可以使神经网络更有效地训练.
Below is a plot of a ReLU function.

正如您所看到的,这个ReLU函数只是将负值更改为零. This 有助于防止梯度消失问题. 如果梯度消失,它不会对神经网络的权重调整产生很大的影响.
卷积神经网络由多层组成:卷积层, ReLU layers, and fully connected layers. 完全连接层将一层中的每个神经元连接到另一层中的每个神经元, 正如在本节开始时看到的图像中的两个隐藏层. 最后一个完全连接层将前一层的输出映射到,在这种情况下, number_of_actions values.
深度学习是成功的,并且在几个机器学习子领域中优于经典机器学习算法, including computer vision, speech recognition, and reinforcement learning. 这些领域的深度学习应用于各种现实世界的领域:金融, medicine, entertainment, etc.
强化学习是基于 agent. 代理在环境中采取行动,并从中获得观察和奖励. agent需要被训练去最大化累积奖励. As noted in the introduction, 用经典的机器学习算法, 机器学习工程师需要做特征提取, i.e., 创造良好的特征,很好地代表环境,并将其输入机器学习算法.
Using deep learning, 有可能创建一个端到端的系统,它接受高维输入e.g. 视频,并从中学习代理采取良好行动的最佳策略.
In 2013, 伦敦人工智能初创公司DeepMind在学习直接从高维感官输入控制代理方面取得了重大突破. They published a paper, 用深度强化学习玩Atari, 他们展示了如何教人工神经网络只需要看屏幕就能玩雅达利游戏. 他们被b谷歌收购,然后在 Nature with some improvements: 通过深度强化学习实现人类水平的控制.
与其他机器学习范例相反, 强化学习没有管理者, only a reward signal. 反馈是延迟的:它不像监督学习算法那样是即时的. 数据是连续的,代理的操作会影响它接收到的后续数据.
现在,一个行为人处于它所处的环境中,这个环境处于某种状态. 为了更详细地描述这一点,我们使用马尔可夫决策过程,它是 一个正式的方法来建模这个强化学习环境. 它由一组状态、一组可能的动作和规则组成.g.(概率)从一个状态转换到另一个状态.

代理能够执行动作,改变环境. We call the reward $ R_t $. 它是一个标量反馈信号,表示agent在步骤t上做得有多好.

For good long-term performance, 不仅要考虑眼前的回报,还要考虑将来的回报. 从时间步$t$开始的一个情节的总奖励是$ R_t = R_t + r_{t+1} + r_{t+2} + \ldots + r_n $. 未来是不确定的,我们在未来走得越远,对未来的预测就越有可能出现分歧. Because of that, 使用贴现的未来奖励:$ R_t = R_t +\gamma r_{t+1} +\gamma ^2r_{t+2} +\ ldots +\gamma ^{n-t}r_n = R_t +\gamma r_{t+1} $. 代理人应该选择使未来折现收益最大化的行为.
The $ Q(s, A) $函数表示执行动作$ A $时的最大贴现未来奖励
对未来奖励的估计由Bellman方程给出:$ Q(s), a) = r + \gamma \max_{a’}Q(s’, a’) $ . In other words, 给定状态$ s $和动作$ a $的最大未来奖励是即时奖励加上下一状态的最大未来奖励.
用非线性函数(神经网络)逼近q值不是很稳定. 正因为如此,经验重放被用来保持稳定性. 训练过程中的经验会储存在回放存储器中. 使用重播内存中的随机小批量,而不是使用最近的转换. 这打破了后续训练样本的相似性,否则将使神经网络进入局部最小值.
关于深度q学习,还有两个更重要的方面需要提及:探索和开发. 通过利用,可以在给定当前信息的情况下做出最佳决策. Exploration gathers more information.
当算法执行由神经网络提出的动作时, 它在做开发:它利用神经网络的学习知识. In contrast, an algorithm can take a random action, 探索新的可能性并将潜在的新知识引入神经网络.
DeepMind论文中的“带经验回放的深度q学习算法” 用深度强化学习玩Atari is shown below.

DeepMind将用他们的方法训练的卷积网络称为深度q网络(Deep Q-networks, DQN)。.
《欧博体育app下载》是一款受欢迎的手机游戏,最初由越南电子游戏艺术家和程序员Dong Nguyen开发. 在这款游戏中,玩家控制一只鸟,并尝试在绿色管道之间飞行而不击中它们.
Below is a screenshot from a Flappy Bird clone coded using PyGame:

克隆已经被分叉和修改:背景, sounds, 不同的鸟和管道样式已经被删除,代码已经调整,所以它可以很容易地与简单的强化学习框架一起使用. The modified game engine is taken from this TensorFlow project:

但是我没有使用TensorFlow,而是使用PyTorch构建了一个深度强化学习框架. PyTorch是一个深度学习框架,用于快速、灵活的实验. 它提供了张量和动态神经网络 Python with strong GPU acceleration.
神经网络架构与DeepMind在论文中使用的相同 通过深度强化学习实现人类水平的控制.
| Layer | Input | Filter size | Stride | Number of filters | Activation | Output |
|---|---|---|---|---|---|---|
| conv1 | 84x84x4 | 8x8 | 4 | 32 | ReLU | 20x20x32 |
| conv2 | 20x20x32 | 4x4 | 2 | 64 | ReLU | 9x9x64 |
| conv3 | 9x9x64 | 3x3 | 1 | 64 | ReLU | 7x7x64 |
| fc4 | 7x7x64 | 512 | ReLU | 512 | ||
| fc5 | 512 | 2 | Linear | 2 |
有三个卷积层和两个全连接层. 除了最后一层使用线性激活外,每一层都使用ReLU激活. 神经网络输出两个值,代表玩家唯一可能的行动:“飞起来”和“什么都不做”.”
输入由四个连续的84x84黑白图像组成. 下面是输入到神经网络的四幅图像的例子.
你会注意到图像是旋转的. 这是因为克隆游戏引擎的输出是旋转的. 但如果神经网络被教导,然后用这些图像进行测试, it will not affect its performance.

你可能还注意到图像被裁剪了,所以地板被省略了, because it is irrelevant for this task. 所有代表管道和鸟的像素都是白色的,所有代表背景的像素都是黑色的.
这是定义神经网络的一部分代码. 神经网络的权重被初始化为遵循均匀分布$\mathcal{U}(-0).01, 0.01)$. 神经网络参数的偏置部分设为0.01. Several different initializations were tried (Xavier uniform, Xavier normal, Kaiming uniform, Kaiming normal, uniform, and normal), 但上述初始化使神经网络收敛,训练速度最快. The size of the neural network is 6.8 MB.
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.number_of_actions = 2
self.gamma = 0.99
self.final_epsilon = 0.0001
self.initial_epsilon = 0.1
self.number_of_iterations = 2000000
self.replay_memory_size = 10000
self.minibatch_size = 32
self.conv1 = nn.Conv2d(4, 32, 8, 4)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32, 64, 4, 2)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(64, 64, 3, 1)
self.relu3 = nn.ReLU(inplace=True)
self.fc4 = nn.Linear(3136, 512)
self.relu4 = nn.ReLU(inplace=True)
self.fc5 = nn.Linear(512, self.number_of_actions)
def forward(self, x):
out = self.conv1(x)
out = self.relu1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.conv3(out)
out = self.relu3(out)
out = out.view(out.size()[0], -1)
out = self.fc4(out)
out = self.relu4(out)
out = self.fc5(out)
return out
在构造函数中,您会注意到定义了超参数. 超参数优化不是本文的目的. 相反,超参数主要来自DeepMind的论文. Here, 一些超参数被缩小到比DeepMind论文中的更小, 因为《欧博体育app下载》没有他们用来调优的雅达利游戏复杂.
同时,对于这个游戏来说,变的更加合理. DeepMind用的是1,但这里用的是0.1. 这是因为更高的epsilons迫使鸟拍打很多, 哪个将鸟推向屏幕的上边界, 最后总是导致鸟撞到管道上.
强化学习代码有两种模式:训练模式和测试模式. During the test phase, 我们可以看到强化学习算法如何很好地学会了玩这个游戏. 但首先,神经网络需要被训练. 我们需要定义要最小化的损失函数和最小化损失函数的优化器. We’ll use the Adam 损失函数的优化方法及均方误差:
optimizer = optim.Adam(model.parameters(), lr=1e-6)
criterion = nn.MSELoss()
The game should be instantiated:
game_state = GameState()
重放内存被定义为Python列表:
replay_memory = []
现在我们需要初始化第一个状态. An action is two-dimensional tensor:
The frame_step 方法为我们提供下一个屏幕、奖励以及关于下一个状态是否为终端的信息. The reward is 0.1 每只鸟在没有穿过管道的情况下没有死亡, 1 如果鸟成功地通过了管道 -1 if the bird crashes.
The resize_and_bgr2gray function crops the floor, resizes screen to an 84x84 image, 并将颜色空间从BGR更改为黑白. The image_to_tensor 函数将图像转换为PyTorch张量,并在CUDA可用时将其放入GPU内存. Finally, 最后四个连续的屏幕连接在一起,准备发送给神经网络.
action = torch.zeros([model.number_of_actions], dtype=torch.float32)
action[0] = 1
Image_data, reward, terminal = game_state.frame_step(action)
Image_data = resize_and_bgr2gray(Image_data)
image_data = image_to_tensor(image_data)
state = torch.Cat ((image_data, image_data, image_data, image_data)).unsqueeze(0)
初始的epsilon是用这行代码设置的:
epsilon = model.initial_epsilon
The main infinite loop follows. 注释写在代码中,你可以将代码与上面写的Deep Q-learning with Experience Replay算法进行比较.
该算法从重播存储器中提取小批量样本,并更新神经网络的参数. Actions are executed using epsilon greedy exploration. Epsilon is being annealed over time. 被最小化的损失函数为$ L = \frac{1}{2}\left[\max_{a '}Q(s ', a ') - Q(s, a)\right]^2 $ . $ Q(s, a) $是使用Bellman方程和$ \max_{a '}Q(s ')计算的基础真值, A ') $是由神经网络得到的. 神经网络对两种可能的动作给出两个q值,算法采取q值最高的动作.
while iteration < model.number_of_iterations:
# get output from the neural network
output = model(state)[0]
# initialize action
action = torch.zeros([model.number_of_actions], dtype=torch.float32)
if torch.cuda.is_available(): #如果CUDA可用,则放置GPU
action = action.cuda()
# epsilon greedy exploration
random_action = random.random() <= epsilon
if random_action:
print("Performed random action!")
action_index = [torch.randint(model.number_of_actions, torch.Size([]), dtype=torch.int)
if random_action
else torch.argmax(output)][0]
if torch.cuda.is_available(): #如果CUDA可用,则放置GPU
action_index = action_index.cuda()
action[action_index] = 1
# get next state and reward
Image_data_1,奖励,终端= game_state.frame_step(action)
Image_data_1 = resize_and_bgr2gray(Image_data_1)
Image_data_1 = image_to_tensor(Image_data_1)
state_1 = torch.cat((state.squeeze(0)[1:, :, :], image_data_1)).unsqueeze(0)
action = action.unsqueeze(0)
reward = torch.from_numpy(np.array([reward], dtype=np.float32)).unsqueeze(0)
# save transition to replay memory
replay_memory.追加((state, action, reward, state_1, terminal))
#如果重放内存已满,删除最旧的过渡段
if len(replay_memory) > model.replay_memory_size:
replay_memory.pop(0)
# epsilon annealing
epsilon = epsilon_decrements[iteration]
# sample random minibatch
minibatch = random.Sample (replay_memory, min(len(replay_memory)), model.minibatch_size))
# unpack minibatch
state_batch = torch.cat(tuple(d[0] for d in minibatch))
action_batch = torch.cat(tuple(d[1] for d in minibatch))
reward_batch = torch.cat(tuple(d[2] for d in minibatch))
state_1_batch = torch.cat(tuple(d[3] for d in minibatch))
if torch.cuda.is_available(): #如果CUDA可用,则放置GPU
state_batch = state_batch.cuda()
action_batch = action_batch.cuda()
reward_batch = reward_batch.cuda()
state_1_batch = state_1_batch.cuda()
# get output for the next state
output_1_batch = model(state_1_batch)
#设置y_j为r_j,否则为r_j + gamma*max(Q)
y_batch = torch.Cat (tuple(reward_batch[i] if minibatch[i]
else reward_batch[i] + model.gamma * torch.max(output_1_batch[i])
for i in range(len(minibatch))))
# extract Q-value
q_value = torch.Sum (model(state_batch) * action_batch, dim=1)
# PyTorch默认累积渐变,所以它们需要在每次传递中重置
optimizer.zero_grad()
#返回一个新的张量,与当前图形分离,结果将永远不需要梯度
y_batch = y_batch.detach()
# calculate loss
loss = criterion(q_value, y_batch)
# do backward pass
loss.backward()
optimizer.step()
# set state to be state_1
state = state_1
Now that all the pieces are in place, 以下是使用我们的神经网络的数据流的高级概述:

这是一个经过训练的神经网络的短序列.

The neural network shown above was trained using a high-end Nvidia GTX 1080 GPU for a few hours; using a CPU-based solution instead, 这项特别的任务需要好几天的时间. 游戏引擎的FPS在训练期间被设置为非常大的数值:999……999——换句话说, as many frames per second as possible. In testing phase, the FPS was set to 30.
下面的图表显示了迭代期间最大q值的变化情况. Every 10,000th iteration is shown. 向下的尖峰意味着对于一个特定的帧(一次迭代是一帧),神经网络预测这只鸟在未来会得到非常低的奖励——1.e., it will crash very soon.

完整的代码和预训练模型是可用的 here.
在这个PyTorch强化学习教程中, 我展示了电脑如何在没有任何游戏知识的情况下学会玩《欧博体育app下载》, 就像人类第一次遇到游戏时那样,只使用试错法.
有趣的是,该算法可以使用PyTorch框架在几行代码中实现. 本博客中方法所基于的论文相对较老, 有很多更新的论文进行了各种修改,可以更快地收敛. Since then, 深度强化学习已经被用于玩3D游戏和现实世界的机器人系统.
Companies like DeepMind, Maluuba, and Vicarious 正在深入研究深度强化学习吗. AlphaGo使用了这种技术,它击败了世界上最好的围棋选手之一李世石. At the time, 当时人们认为,机器至少需要十年的时间才能打败最好的围棋选手.
对深度强化学习(以及一般的人工智能)的兴趣和投资甚至可能导致潜在的人工智能 general 人工智能(AGI)——人类水平的智能(甚至更高),可以用算法的形式表达,并在计算机上模拟. 但AGI将不得不成为另一篇文章的主题.
References:
无监督学习是机器学习的一种方法,它在数据中发现结构. 与监督式学习不同,数据没有标记.
在被动强化学习中,智能体学习并遵循策略. 它得到“奖励”,但只能观察它们,不管它们是好是坏. In contrast, 主动强化学习让智能体学会在每个状态下采取最佳行动,以最大化累积的未来奖励.
In reinforcement learning, agent每次在环境中的某些状态下采取某些行动时,都可以获得“奖励”形式的反馈. 逆强化学习试图根据特定状态下的行为所获得的奖励历史来重建奖励函数.
许多神经网络类型都是基于它们所使用的层的组合.g. 卷积层,全连接层和LSTM层. 神经网络的类型包括卷积神经网络(cnn), recurrent neural networks (RNNs), 以及多层感知器(MLP或“香草”)神经网络.
DeepMind科技有限公司是一家位于伦敦的人工智能公司. 他们开发了AlphaGo,并击败了世界围棋冠军李世石. 该公司于2014年被b谷歌收购.
Located in Zagreb, Croatia
Member since September 27, 2017
Co-founder of Poze and CEO of an AI R&Neven拥有MCS学位,并在TensorFlow中建立了一个面部识别系统.
 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.7
World-class articles, delivered weekly.
World-class articles, delivered weekly.
Join the Toptal® community.
